博士项目的一些“小数据”
现在比较流行“大数据”,我这个三年的博士只能做点小数据…当初在 Bitbucket 上为自己博士开个 repository 的时候,一方面是因为 EDF 用不了 Dropbox 无法同步资料(或者备份资料吧);一方面就是有个对每天工作的 suivi,知道每天干了什么,如果今后做错了可以回到之前的东西;最后就是想到最后可以对博士项目进行下统计..看自己是怎么工作的。
所以就用 Python 做了个简单的 script,主要是用到 Mercurial 的基本日志功能 hg log,然后是用的 pandas 做直方图的统计(因为数据不一定是数,而是字符串)。由于我第一年换过 repository,所以要把之前一个的 commits 算上。
首先要说一下,每个 commit 不是平等的…有些 commit 肯定比其他 commit 重要(比如修改文件数量很多,添加了很多新东西),而有些就是简单的 merge…这里就不区分了,把每次 commit 就看成是一次活,我们关心的是 commit 在时间上的分布,分析我的工作规律..
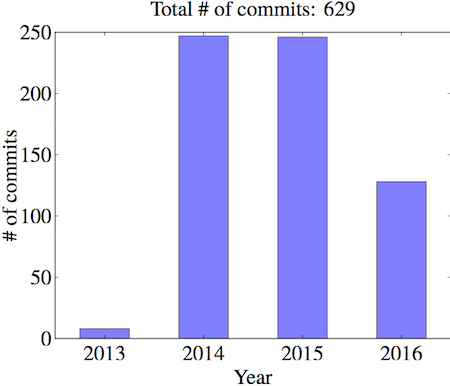
年
首先从 2013 年 10 月份博士开始到现在,一共有过 629 次 commit,统计的大数定律出现了,很巧每年(完整年)大致的 commit 数量都差不多(或者说每天平均?)。比如很巧的是 2014 年和 15 年几乎一样,都差不多 250 个 commit。今年差不多一半了,就差不多 125 个…
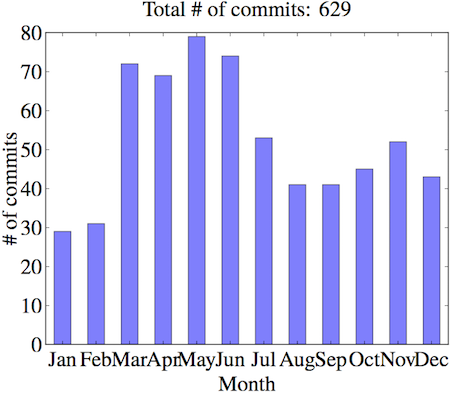
月
很有意思的是春天(3、4、5 月)我的效率最高(重申这里效率的定义是 commits 数量…),而效率最低的是冬天(12、1、2月)…特别是 2 月到 3 月一个猛涨…个人推测是由于我好像几次 2 月份回国过春节而已…
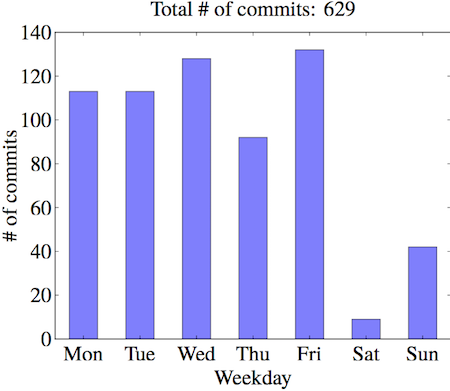
星期
周三达到一个小高峰,不知为什么周四下降(憧憬周末了?),周五达到最高值,个人认为是固定思维要做一个 commit 为了可能周末可以工作…
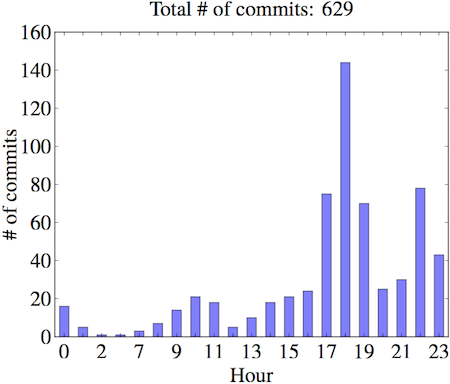
小时
可以说两点:
- 主要集中在下班时间(17 点-19 点),记录今天工作结果
- 其次说明我下班后有时候还工作…睡觉前再来一个 commit 然后第二天继续工作…
最后给出源代码,去掉和 old-commits 相关的东西应该可以适用任何用 Mercurial 管理的 repository。
from homepylab import *
import pandas
from collections import Counter
import subprocess
import os
out = subprocess.check_output(["hg", "log"])
fold = open("old-commits", "r")
f = open("out", "w")
f.writelines(out)
for line in fold:
f.write(line)
f.close()
f = open("out", "r")
weekday = []
month = []
year = []
hour = []
day = []
for line in f:
if line.startswith("date"):
data = line.split()
weekday.append(data[1])
month.append(data[2])
year.append(data[5])
hour.append(int(data[4].split(":")[0]))
day.append(int(data[3]))
for item in ["weekday", "month", "year", "hour", "day"]:
figure()
letter_counts = Counter(eval(item))
df = pandas.DataFrame.from_dict(letter_counts, orient="index")
if item == "weekday":
index = [u'Mon', u'Tue', u'Wed', u'Thu', u'Fri', u'Sat', u'Sun']
df = df.reindex(index)
elif item == "month":
index = [u'Jan', u'Feb', u'Mar', u'Apr', u'May', u'Jun', u'Jul', u'Aug', u'Sep', u'Oct', u'Nov', u'Dec']
df = df.reindex(index)
elif item == "year":
index = ["2013", "2014", "2015", "2016"]
df = df.reindex(index)
fig = df.plot(kind="bar", legend=False, alpha=0.5, rot=0)
ylabel(r"\# of commits")
xlabel(item.capitalize())
title(r"Total \# of commits: %d" %(len(eval(item)))).set_y(1.04)
savefig("nbcommits_%s.ipe" %(item))
os.remove("out")
留下评论